Implementing LDA
Lately I was playing with Latent Dirichlet Allocation (LDA) for a project at work. If for whatever reason you need to implement such algorithm perhaps you will save some time reading the walkthrough I did.
First you must be sure that LDA is the algorithm you are looking for. From a corpus of documents you will get K lists with words from your documents in them with a number assigned to each word denoting the relevance of the given word in the lists. Each list represents a topic, and that would be your topic description, no fancy words like “Computers”, “Biology” or “Life meaning”, just a set of words that a human must interpret. You could always assign a single name by picking the most prominent word in the list or treating the list as a valued vector and comparing it against a canonical topic description. So take a look at the first examples in this presentation and get inspired.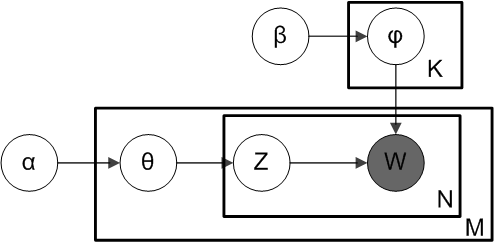
OK so you need some code to test how this method behaves with your particular data. The first thing to try is the topicmodels package from the R statistical software package. This can give you an idea of the method and try to use it in a more serious Java application by means of the Mallet library.
But say that you need to create your own implementation because Java horrifies you or because you need a parallel version or whatever the reason. The first thing you have to do is to choose the inference method of your model between variational methods or gibbs sampling.This post will give you some ideas for picking the right method for your particular problem. The original papers picked the variational approach but I went through the Gibbs sampling method because I found this paper where all the mathematical derivations are nailed down. That way I was able to fully understand the method and at the same time being sure that my implementation was right and sound. If you need more guidance, take a look at this simple implementation for getting an idea of the main functions and data structures you’ll have to code.
Once you have your code written you will have to check whether it is correct or not. The example in this paper using pixel positions and pixel intensities instead of words and word counts is very illustrating and will show visually the correctness of your implementation. Once you have your algorithm up and running perhaps you want to scale it up to more machines, so you could benefit from reading this paper and taking also a look at this blog post from Alex Smola and their distributed implementation of LDA on Github.
Happy coding!!!